Threading
At a glance
The Texture philosophy is about efficient utilization of resources in order to provide a high frame rate user experience. In other words, an almost scientific approach to distributing work amongst threads keeps the Default Run Loop lean to allow user input events and to consume work scheduled on the main dispatch queue.
There are a few conventions to follow:
- Invocations of the UIKit API must happen on the main thread via either
dispatch_get_main_queue()or withASPerformBlockOnMainThread() - Anything else should generally happen on a background thread, with prioritization
Run Loop, Threads, and Queues
A thread is managed by the kernel to execute code. A dispatch_queue_t describes a context for an ordered list of blocks to be executed. A queue may utilize specific thread for execution determined by GCD and the kernel.
A run loop is created per thread if required. Selectors and timers can be attached to a run loop. The main thread’s run loop is iterated through automatically, background threads’ run loops need to be looped explicitly, and may not necessarily exist without prior access. A thread has only one run loop.
When using dispatch_async for a background queue, GCD (Grand Central Dispatch) will ask the kernel for a thread, where the kernel either creates one, picks an idle thread, or waits for one to become idle. These threads, once created, live in the thread pool. You should never have to call directly to a thread, they are abstracted to you by GCD.
Dispatch Queue Playgrounds
self.queue1 = dispatch_queue_create("multitask.1", DISPATCH_QUEUE_SERIAL);
This creates a dispatch_queue_t. This is an Objective-C object, managed by ARC. When you startup LLDB, you will notice that there is no designated thread for this queue. That is because a thread is only created if GCD asks the kernel for a thread when work is scheduled.
dispatch_async(self.queue1, ^{
NSLog(@"I love robustly distributed work");
});
After performing the above operation, a thread is created to perform your work. A thread creation time is roughly 90 microseconds according to Apple. After this has executed and you see the statement in the debugger, starting LLDB and running (lldb) thread list shows that there should be an additional background thread with no associated queue. This is because a thread is created and added to the pool, however the queue is detached from the thread until needed again.
dispatch_async(self.queue1, ^{
while (true) {
NSLog(@"I love robustly distributed work");
}
});
Starting LLDB while the statements are printing and running (lldb) thread list shows a list of threads, one which has an associated queue, in this case our queue multitask.1.
dispatch_async(self.queue1, ^{
printf("block 1\n");
});
dispatch_async(self.queue1, ^{
printf("block 2\n");
});
For this example, we add some autocontinue breakpoints that run a command thread info on both of the print statements. Running the program shows the two block invocations are executed on the same thread.
Let’s see what kind of behavior GCD exhibits:
self.queueA = dispatch_queue_create("multitask.A", DISPATCH_QUEUE_SERIAL);
self.queueB = dispatch_queue_create("multitask.B", DISPATCH_QUEUE_SERIAL);
dispatch_async(self.queueA, ^{
printf("A: block 1\n");
});
dispatch_async(self.queueA, ^{
printf("A: block 2\n");
});
dispatch_async(self.queueB, ^{
printf("B: block 1\n");
});
dispatch_async(self.queueB, ^{
printf("B: block 2\n");
});
outputs the following:
thread #2: tid = 0x32a3e6, 0x000000010adf4457 ThreadingFun`__29-[ViewController viewDidLoad]_block_invoke(.block_descriptor=0x000000010adf6090) at ViewController.m:24, queue = 'multitask.A', stop reason = breakpoint 2.1
thread #3: tid = 0x32a3e7, 0x000000010adf44b7 ThreadingFun`__29-[ViewController viewDidLoad]_block_invoke_3(.block_descriptor=0x000000010adf6110) at ViewController.m:31, queue = 'multitask.B', stop reason = breakpoint 4.1
A: block 1
B: block 1
thread #2: tid = 0x32a3e6, 0x000000010adf4487 ThreadingFun`__29-[ViewController viewDidLoad]_block_invoke_2(.block_descriptor=0x000000010adf60d0) at ViewController.m:27, queue = 'multitask.A', stop reason = breakpoint 3.1
thread #3: tid = 0x32a3e7, 0x000000010adf44e7 ThreadingFun`__29-[ViewController viewDidLoad]_block_invoke_4(.block_descriptor=0x000000010adf6150) at ViewController.m:34, queue = 'multitask.B', stop reason = breakpoint 5.1
A: block 2
B: block 2
So here we can see that GCD elects to create two new threads. It will reuse the thread that pertains to the queue.
So this is when we dispatch work to a queue we created manually. Lets take a look at using dispatch_get_global_queue
Without using LLDB breakpoints to execute thread info. Since running LLDB takes a non-deterministic amount of time, the block execution time may vary producing out of order statements.
dispatch_async(dispatch_get_global_queue(QOS_CLASS_DEFAULT, 0), ^{
printf("block 1\n");
});
dispatch_async(dispatch_get_global_queue(QOS_CLASS_DEFAULT, 0), ^{
printf("block 2\n");
});
dispatch_async(dispatch_get_global_queue(QOS_CLASS_DEFAULT, 0), ^{
printf("block 3\n");
});
dispatch_async(dispatch_get_global_queue(QOS_CLASS_DEFAULT, 0), ^{
printf("block 4\n");
});
produces the following output
block 1
block 2
block 3
block 4
Starting the debugger at the end of the function should show 4 threads, each with the same queue attached. Now GCD is federating your work onto threads on demand. How many threads will it create?
for (int i=0; i < 100; i++) {
dispatch_async(dispatch_get_global_queue(QOS_CLASS_DEFAULT, 0), ^{
printf("block %i\n", i);
});
}
Starting the debugger approximately 500ms after the completion of the for loop shows that there are 64 threads in the thread pool. The behavior you would experience by the thread pool limit is a delay in block execution after the 64th long-running block has been queued. If you are performing a lot of work, make sure to grab the correct priority queue dispatch_get_global_queue(QOS_CLASS_xxxxxxx, 0) for your needs. Otherwise you may denial-of-service any other blocks looking to be executed later on.
An interesting dive into how cores fit into this picture can be found on Mike Ash’s Observing the A11 heterogenous cores
Here we can do a fun test to understand the recycling behavior of GCD
const int64_t kOneMillion = 1000 * 1000;
static mach_timebase_info_data_t s_timebase_info;
static dispatch_once_t onceToken;
dispatch_once(&onceToken, ^{
(void) mach_timebase_info(&s_timebase_info);
});
for (int i=0; i < 1000; i++) {
uint64_t start = mach_absolute_time();
dispatch_async(dispatch_get_global_queue(QOS_CLASS_DEFAULT, 0), ^{
uint64_t end = mach_absolute_time();
uint64_t elapsed = end - start;
uint64_t nanosec = elapsed * s_timebase_info.numer / s_timebase_info.denom;
printf("%llu ms block %i\n", nanosec / kOneMillion, i);
usleep(10000);
});
}
Looking at the logs, we can see how GCD reaches a maximum background thread count, varied by CPU. This example was run on the 8 core Macbook Pro
1 ms block 62
1 ms block 63
10 ms block 65
10 ms block 66
10 ms block 64
ASMainSerialQueue
The ASMainSerialQueue ensures that work can be performed serially on the main thread without being interrupted. The key difference between this and purely using dispatch_async(dispatch_get_main_queue, block) is that the main thread can be interrupted between execution of blocks in its queue, where as this interface will execute everything possible in its queue on the main thread before returning control back to the OS.
This interface calls to ASPerformBlockOnMainThread. This interface will lock out other threads attempting to schedule work while it is popping the next block to be consumed on the main thread. New blocks scheduled while existing ones are executing are guaranteed to be executed during that run loop, i.e. before anything else even on main dispatch queue or the Default Run Loop are consumed.
This should also be used a synchronization mechanism. Since the ASMainSerialQueue is serial, you can be sure that it will execute in order. An example would be to queue the following blocks: change view property -> trigger layout update -> animate. Remember that funny situations can occur since execution of work on ASMainSerialQueue can early execute blocks that were scheduled later than blocks sent using dispatch_async(dispatch_get_main_queue()) if the ASMainSerialQueue is already consuming blocks. The execution time of the [ASMainSerialQueue runBlocks] is uncertain given that more work can be scheduled.
This is really just a buffer to the main dispatch queue. It behaves the same, except this offers some more visibility onto how much work is scheduled. This interface guarantees that everything scheduled will execute in one operation serially on the main thread.
ASRunLoopQueue
Even deallocation of UIKit objects on the main thread are optimized in Texture. Usually, synchronously, objects are retain counted and freed from memory when appropriate. This just isnt’t good enough for a performant framework like Texture. So instead, for each run loop iteration on the main thread, a maximum set of objects can be designated to be freed. This is done by calling void ASPerformMainThreadDeallocation(id _Nullable __strong * _Nonnull objectPtr). Behind the scenes, this is using ASRunLoopQueue ensuring that only a maximum amount of objects are deallocated, and that this occurs at the least demanding time on the run loop. Let’s break down its initializer:
// Self is guaranteed to outlive the observer. Without the high cost of a weak pointer,
// __unsafe_unretained allows us to avoid flagging the memory cycle detector.
__unsafe_unretained __typeof__(self) weakSelf = self;
void (^handlerBlock) (CFRunLoopObserverRef observer, CFRunLoopActivity activity) = ^(CFRunLoopObserverRef observer, CFRunLoopActivity activity) {
[weakSelf processQueue];
};
Why __unsafe__unretained?
_runLoopObserver = CFRunLoopObserverCreateWithHandler(NULL, kCFRunLoopBeforeWaiting, true, 0, handlerBlock);
CFRunLoopAddObserver(_runLoop, _runLoopObserver, kCFRunLoopCommonModes);
This creates a run loop observer that can be added to the targeted run loop, in this case always the main thread’s run loop. The kCFRunLoopBeforeWaiting places the call to this observer just after the run loop has finished processing the other inputs and sources and just before it will be put to sleep. This ensures that high priority tasks such as responding to user events such as touches are handled first.
However, there is one nuance to using kCFRunLoopBeforeWaiting, the handler will not be called if there were no inputs or sources to wake up the run loop again in a situation where the deallocation has to be batched. In order to wake the run loop for another cycle, we introduce a no-op source so that there is “work” to be performed for each iteration of the run loop and then invoke the Core Foundation API to iterate the run loop.
static void runLoopSourceCallback(void *info) {
// No-op
}
...
CFRunLoopSourceContext sourceContext = {};
sourceContext.perform = runLoopSourceCallback;
_runLoopSource = CFRunLoopSourceCreate(NULL, 0, &sourceContext);
CFRunLoopAddSource(runloop, _runLoopSource, kCFRunLoopCommonModes);
At the end of each processQueue invocation, if we still have more objects to process (exceeded the deallocation batch size), then we use this at the end of the processQueue to begin another run loop iteration.
if (!isQueueDrained) {
CFRunLoopSourceSignal(_runLoopSource);
CFRunLoopWakeUp(_runLoop);
}
Locks and Safety
Carrying on from our last example, we have to make sure that during our processing of the queue for objects that need to be deallocated remains untampered to avoid bounds errors. The execution of this function must be synchronous. In this particular example, we can guarantee that the execution of this will always happen on a designated run loop’s single thread, and therefore synchronously. However, we want to design robust software that won’t deadlock or crash.
Method 1
Looking at -(void)processQueue, we have the following locking convention:
@interface ASRunLoopQueue () {
ASDN::RecursiveMutex _internalQueueLock;
}
ASSynthesizeLockingMethodsWithMutex(_internalQueueLock) // Texture macro for creating the lock
- (void)processQueue
{
{
ASDN::MutexLocker l(_internalQueueLock);
// ... array operations
}
}
ASDN::MutexLocker l(_internalQueueLock); will lock the recursive mutex. This prevents other threads other than the current thread from entering this routine again, which is fine since a thread serially executes. The lock will free itself once the stack frame is popped.
Since this lock is also shared, it will prevent other routines from entering until this lock is released. This is mandatory for safe synchronization of shared objects between threads.
Method 2
ASThread provides ASLockScopeSelf(). This is a convenience over ASLockScopeUnowned(<NSLocking>). This will unlock itself once the scope in which the lock was created is released. Only use this when you are confident that the lock should remain until scope is complete. You can only have one lock defined for self, thus it will block all other branches.
#define ASLockScopeUnowned(nsLocking) \
__unsafe_unretained id<NSLocking> __lockToken __attribute__((cleanup(_ASLockScopeUnownedCleanup))) = nsLocking; \
[__lockToken lock];
ASDISPLAYNODE_INLINE void _ASLockScopeCleanup(id<NSLocking> __strong * const lockPtr) {
[*lockPtr unlock];
}
Usage example
- (ASImageNode *)imageNode
{
ASLockScopeSelf();
if (!_imageNode) {
_imageNode = [[ASImageNode alloc] init];
[_imageNode setLayerBacked:YES];
}
return _imageNode;
}
Thread Contention
Although locks are critical to guaranteeing safer multithreading synchronization, they must be used with some caution, as threads are slept if they can not hold the lock immediately. In order to sleep/wake a thread, many CPU cycles are consumed. Some std::mutex implementations are able to spinlock for a bit at first to combat the overhead of sleeping and waking a thread for failed lock holds. However, the performance loss here is a necessary sacrifice in order to attain thread safety. In order to make up for the potential loss in performance, the programmer should design as little opportunity for contention as possible, and to lock only the smallest amount of work.
An interesting investigation can be found here
Bottom line, a mutex is implemented with atomics. To synchronize atomics between cores an internal bus must be locked which freezes the corresponding cache line for several hundred clock cycles.
Other Threading Practices in Texture
Main Thread/ UIKit API
| API | Description |
|---|---|
ASDisplayNodeAssertMainThread(); |
Place this at the start of the every function definition that performs work synchronously on the main thread. |
ASPerformBlockOnMainThread(block) |
If on main thread already, run block synchronously, otherwise use dispatch_async(dispatch_get_main_queue(block)) |
ASPerformMainThreadDeallocation(&object) |
Schedule async deallocation of UIKit components |
ASPerformBlockOnBackgroundThread(block) |
Perform work on background |
Threading by example
Let’s take a look at collection view. UIKit calls (such as batch updates) can be invoked from the background due to network calls returning with fresh models. These models are then used to calculate a change set used by the collection view to perform a batch update. This batch update calls into UIKit API for insertions, deletions, and moves in one continuous operation that modifies the view hierarchy. As we know, all UIKit operations must occur on the main thread. How can we design the interface to get the most efficient distribution of work?
So we have the following situation:
- A data source that talks and responds to events from the network
- A data source that calculates a change set for the collection view
- A collection view that performs batch updates, calling into UIKit API
- Batch updates must happen serially, as they use transformations rather than clearingAllData
ASDataController
This is our data source that talks to the network. It doesn’t really in Texture, but we can pretend that this interface is receiving invocations from a network object. The network object invokes a completion block created by the ASDataController in a background thread context. This is correct behavior, because we want non-UI related work to happen off of the main thread as much as possible.
Since the data source still needs to have usable data while the network and calculations are occurring, we keep two different data structures: pendingMap and visibleMap. The visibleMap is node map for display on the collection view and the pendingMap is an ephemeral for calculating the change set. The change set is the exact least amount of work required to shuffle the collection view items from the old set to the new set.
Editing Transaction Queue
The Editing Transaction Queue is an example of using a background queue to schedule work that may be long running in a way that won’t block the application from receiving callbacks from the main thread’s Run Loop or other main thread only work such as calls to UIKit API.
This is a dispatch_queue_t that is privately held by each UICollectionView. The work scheduled gets performed on a background thread.
Describing the Batch Update flow

Starting with a simple example, let’s say everything was on the main thread. The app would then appear unresponsive to the user until the entire flow finished. This is because the main thread’s run loop (which receives operating system events for input) and the main thread dispatch queue compete for service time on the main thread. Execution goes back and forth between the run loop and the main dispatch queue while work is present in either. Now you can see that the work your code wants to schedule competes for time with system and user input events.
Let’s identify the items that are not critical for execution on the main thread and dispatch those as blocks onto a background thread.
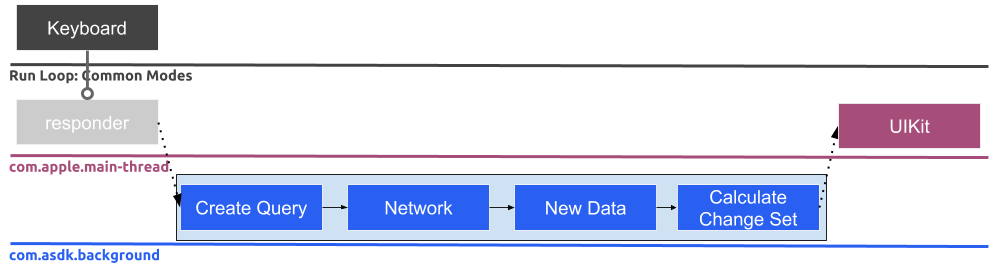
Ok, this is starting to look better. The main thread now only performs the minimal amount of work. This means the app will feel responsive to the user as it is able to consume Run Loop events with little interruption. However, a lot of the background work is still being done serially in one long running operation. If the network is the longest running task in this sequence, you would want to make sure they get fired off as early as possible. Let’s also introduce another condition, we have a NSTimer running which injects a “hint” cell into the collection view. This is to demonstrate how the editing transaction queue is consumed serially.
The reason we must design the work to consume the editing transaction queue serially alongside the main queue is change sets must represent a transformation of the current data set in the collection view. This means that each time a performBatchUpdate is intended to be performed, it must calculate using the latest data set used for display in the collection view. In this following image, this means that change sets can only be calculated from A -> B, and then when performBatchUpdate task is fully finished, another calculation can be done from B -> C. Consider data sets B and C coming in right after the other. If the queues consumed concurrently, then you would get a change set for A -> B and A -> C. The collection view will crash if a change set is requested for A -> C, while a performBatchUpdate is updating the collection view to reflect A -> B with a A -> C operation is queued. All this means that we create a pseudo-lock on the editingTransactionQueue by consuming it one operation at a time, either when the queue is empty or when an operation has finished as called by the completed performBatchUpdate invocation.
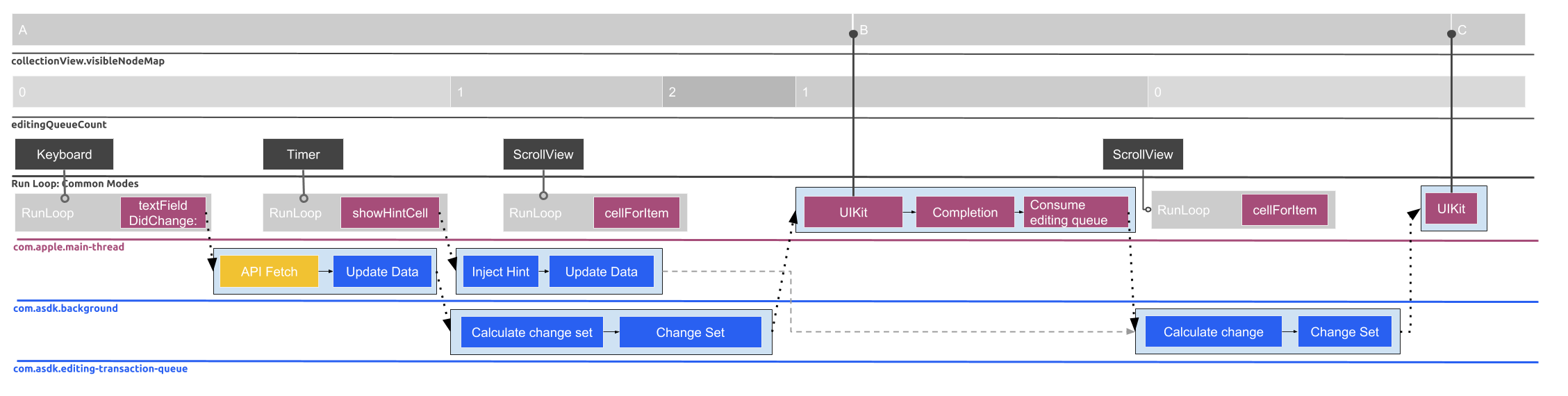
One small note is these diagrams are missing a representation of the main dispatch queue. Remember this is separate from the main thread. It is a data structure operated by GCD similarly to ASMainSerialQueue which handles execution to the main thread. All the work that goes from the background threads to the main thread is first put onto the main dispatch queue when using dispatch_async(dispatch_get_main_queue()).
.